
Porównywanie algorytmów
W literaturze spotyka się różne kryteria porównujące algorytmy. Niektóre z nich to:
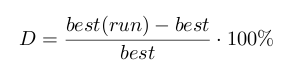
gdzie best(run) - jakość najlepszego rozwiązania w danym przebiegu, best - jakość rozwiązania optymalnego. Kryterium to jest często stosowane, ponieważ pozwala w przybliżony sposób porównać wyniki z różnych instancji testowych.
Ponieważ kryteria nie są od siebie zależne w sposób jawny, jako lepszy algorytm można określić jedynie ten, który przewyższa inny pod względem wszystkich kryteriów. W pozostałych przypadkach można jedynie wyznaczyć zbiór Pareto-optymalny. Przy ocenianiu algorytmów uznano jednak, że współczynnik D najlepiej odzwierciedla skuteczność modelu, podczas gdy pozostałe kryteria mają drugorzędne znaczenie.
Liczba powtórzeń dla pojedynczej instancji
Z uwagi na obszerny zakres testów i długi czas obliczeń, sprawdzono, jaka liczba powtórzeń wykonania obliczeń dla jednej instancji daje statystycznie akceptowalny wynik. Dla dwóch modeli algorytmów przeprowadzono 20 prób dla każdej z 24 instancji. Następnie wyznaczono średnią wartość wskaźnika D dla odpowiednio: 5, 7 i 10 pierwszych prób. Później obliczono różnicę tych średnich ze średnimi wyznaczonymi w 20 próbach. Obliczono maksymalną różnicę, wartość średnią oraz odchylenie standardowe. Wyniki przedstawiają się następująco:
Tablica 4.1: Wpływ liczby powtórzeń testów na wyniki.
| 5 | 7 | 10 | |
| Maksymalna różnica | 5,17% | 2,95% | 1,71% |
| Odchylenie standardowe | 1,4% | 1% | 0,7% |
| Średnia różnica | -0,02% | -0,02% | -0,04% |
Obliczenia zamieszczono na płycie kompaktowej. Na podstawie tej tabeli uznano, iż 5 prób stanowi akceptowalną liczbę prób w stosunku do pojedynczej instancji. W toku testów okazało się, że różnice wynikające z użycia różnych modeli algorytmów są o wiele bardziej znaczące.
Program korzysta z generatora liczb pseudolosowych o nazwie Mersenne Twister. Posiada on bardzo dobre właściwości i jest powszechnie stosowany. Ziarno generatora (ang. seed) można ustawić przed wykonaniem algorytmu, co sprawia, iż wyniki są powtarzalne (za wyjątkiem czasu trwania). Główna pętla programu ustawia ziarno kolejno na wartości od 1313 do 1317.
Po każdym badaniu algorytm bazowy uzupełniano o najlepsze uzyskane usprawnienie. Przy tworzeniu modeli starano się wyizolować badany element, aby nie wpływać na pozostałe.
komentarze
Copyright © 2008-2010 EPrace oraz autorzy prac.