
Implementacja
Poniższy algorytm stanowi wersję bazową, która służy jako podstawa do testowania zmian i badania wpływu różnych jego elementów składowych. Opisano tylko te operatory, które zostały zastosowane w pracy.
Reprezentacja rozwiązania
Rozwiązanie zostało zakodowane w postaci całkowitoliczbowej - wektora liczb reprezentujących kolejne miasta.
π = (π(1),..., π(n)) (3.4)
Dopuszczalnym zbiorem rozwiązań jest zbiór permutacji miast. Przykładowe rozwiązanie dla wielkości zagadnienia 7 wygląda następująco: [5 - 6 - 3 - 1 - 2 - 4 - 7]. Reprezentowana trasa przebiega między miastami sąsiadującymi ze sobą w wektorze, natomiast ostatnie miasto łączy się z pierwszym.
Funkcja przystosowania
Funkcją przystosowania jest funkcja celu o postaci:
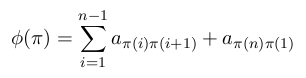
Suma odległości pomiędzy poszczególnymi miastami trasy daje wartość funkcji przystosowania (ang. fitness). Optymalizacja zagadnienia polega na poszukiwaniu minimum.
Topologia
Liczebność całej populacji wynosi Npop. Na całą populację składa się S jednakowych podpo-pulacji o rozmiarze Npodpop, przy czym Npop = S * Npodpop.
Podpopulacje wymieniają się osobnikami według topologii TOP. Spektrum różnych zaimplementowanych topologii można znaleźć w tabeli 5.2.
Selekcja
Selekcja osobników odbywa się w trzech momentach algorytmu:
1. Po ewaluacji osobników następuje selekcja do kolejnej generacji - Selekcja międzygeneracyjna.
2. Po selekcji generacyjnej następuje selekcja między podpopulacjami - Selekcja migracyjna.
3. Po wyborze chromosomów do migracji następuje selekcja osobników w podpopulacji docelowej, które zostaną z niej usunięte, aby zwolnić miejsce dla nadchodzących migrantów -Selekcja osobników do usunięcia.
Selekcja turniejowa
Selekcja turniejowa o rozmiarze r odbywa się poprzez losowych wybranie r osobników i wybór najlepszego spośród nich.
Wybór losowy
Wybór każdego osobnika dokonuje się z jednakowym prawdopodobieństwem.
Operatory
Operator krzyżowania - PMX
Operator PMX nazywany jest także krzyżowaniem z częściowym odwzorowaniem. Przebiega on według następującego algorytmu:
1. Z przedziału [1, maxCrossoverLength] losuj długość segmentu krzyżowania crossLength (maxCrossoverLength < n).
2. Losuj locus1 z przedziału [1, n - crossLength].
3. locus2 := locus1 + crossLength
4. SegmentParent1 := Parent1[locus1, locus2]
5. SegmentParent2 := Parent2[locus1, locus2]
for all locus = 1 .. n do
soughtAllele = Parent1[locus]
if (SegmentParent1 zawiera soughtAllele) then
newLocus := pozycja soughtAllele w SegmentParent1
newAllele := SegmentParent2[newLocus]
else if
(SegmentParent2 zawiera soughtAllele) then
newSoughtForAllele := soughtAllele
while (SegmentParent2 zawiera newSoughtAllele) do
newLocus := pozycja newSoughtAllele w SegmentParent2
newSoughtAllele := SegmentParent1[newLocus]
end while
newAllele := newSoughtAllele
else
newAllele := soughtAllele
end if
Child[locus] := newAllele
end for
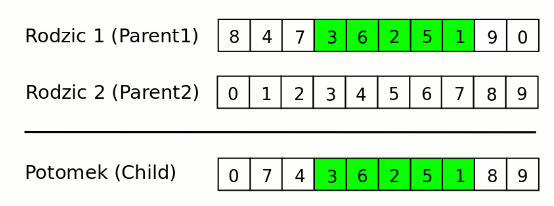
Rysunek 3.1: Przykład działania operatora PMX
Analogicznie tworzy się drugiego potomka, lecz tym razem wybierany jest przedział z drugiego rodzica.
Zaimplementowano także operatory OX i CX, których opis można znaleźć w [14] oraz krzyżowanie GSX ([35]). W testach pomocniczych spośród wszystkich czterech operatorów najbardziej skuteczny okazał się PMX, więc został on wybrany do algorytmu bazowego. Krzyżowanie zachodzi z prawdopodobieństwem Pc.
Operator mutacji - inwersja
Inwersja polega na odwróceniu fragmentu trasy o losowej długości i losowym rozmieszczeniu. Zachodzi z prawdopodobieństwem Pm.
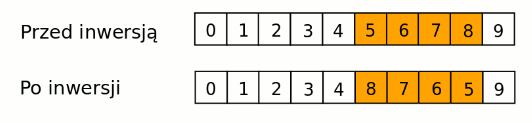
Rysunek 3.2: Przykład działania operatora inwersji
Rozważano także użycie prostej mutacji zamiany dwóch miast (ang. swap), lecz po zastosowaniu jej uzyskano gorsze rezultaty.
Ponadto zaimplementowano heurystykę 2opt (por. [35]) będącą operatorem unarnym. Heury-styki używane są często w miejsce operatorów mutacji. 2opt należy do rodziny heurystyk Lin-Kernighan (por. [25]). Okazała się niezwykle skuteczna, szczególnie przy wysokim współczynniku prawdopodobieństwa mutacji (nawet równym 1). Jednak użycie jej w testach znacznie zniekształciłoby wyniki:
Z powyższych powodów, mimo wysokiej jakości generowanych rozwiązań, zrezygnowano z użycia heurystyki na rzecz klasycznego operatora mutacji.
Kryteria zakończenia obliczeń
Użyto trzech kryteriów stopu algorytmu, przy czym spełnienie któregokolwiek z nich skutkuje zakończeniem obliczeń:
1. Znalezienie rozwiązania optymalnego.
2. Nieznalezienie lepszego od dotychczas najlepszego rozwiązania przez Inoimprov kolejnych generacji.
3. Upłynięcie I max generacji.
Granica dwóch tysięcy generacji została wyznaczona w testach pomocniczych na przykładzie docelowych instacji. Przyrost jakości po przekroczeniu tej granicy był znikomy i występował w niewielkiej liczbie przypadków.
komentarze
Według mnie algorytm podany przez Autora artykułu jest błędny. Czy autor próbował implementować na jego podstawie program?
Wrzucam swoją implementację w języku R, ponieważ zauważyłem w Internecie brak przykładowych implementacji.
http://pastebin.com/7FMfrzfp
skomentowano: 2013-01-06 00:00:36 przez: Przemek
Copyright © 2008-2010 EPrace oraz autorzy prac.